سيقوم Microsoft VALL-E بتقليد صوتنا بعد 3 ثوانٍ فقط من التحدث

في غضون 3 ثوانٍ فقط ، يمكن للذكاء الاصطناعي الذي لم يسمعك من قبل أنك تتحدث تقليد صوتك تمامًا. هذا هو أحدث إنجاز للذكاء الاصطناعي من Microsoft - نموذج تحويل النص إلى كلام VALL-E ، والذي يمكنه نسخ صوت أي شخص كما يشاء في 3 ثوانٍ فقط من الكلام.
سيقوم Microsoft VALL-E بتقليد صوتنا بعد 3 ثوانٍ فقط من التحدث
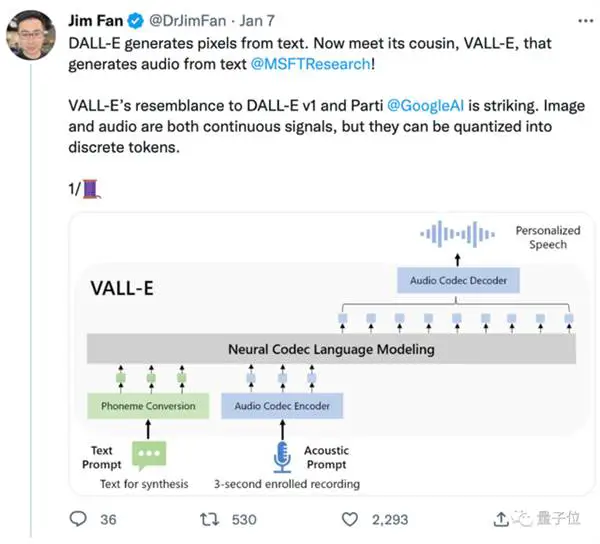
نشأت من DALL E ، لكنها متخصصة في مجال الصوت ، وأصبح تأثير تحويل النص إلى كلام شائعًا بعد إصداره عبر الإنترنت.
قال بعض المستخدمين إنه إذا تم الجمع بين VALL · E و ChatGPT ، فستكون النتيجة مذهلة. بالنسبة للآخرين ، يبدو أن اليوم الذي يمكن فيه إجراء مكالمات فيديو باستخدام الذكاء الاصطناعي ليس بعيدًا. حتى أن هناك من يمزح أنه بعد أن اهتمت منظمة العفو الدولية بالكتاب والرسامين ، يليهم ممثلو الصوت.

ولكن كيف يقلد VALL · E الصوت "غير المسموع" في 3 ثوانٍ؟
يحلل VALL-E الصوت باستخدام نماذج اللغة. يقوم بتوليف الكلام بناءً على أصوات الذكاء الاصطناعي "غير المسموعة" ، أي التعلم بدون عينة.
الحل التقليدي لتحويل النص إلى كلام هو في الأساس وضع ما قبل التمرين جنبًا إلى جنب مع الضبط الدقيق. إذا تم استخدامه في سيناريو عينة صفرية ، فسوف ينتج عنه تشابه ضعيف وطبيعية للخطاب الذي تم إنشاؤه.

بناءً على ذلك ، خرج VALL-E من العدم ، واقترح فكرة مختلفة عن النموذج الصوتي التقليدي.
بالمقارنة مع النموذج التقليدي الذي يستخدم طيف ميل لاستخراج الميزات ، يأخذ VALL-E مباشرة تركيب الكلام كمهمة لنموذج اللغة ، الأول مستمر والأخير منفصل.
على وجه الخصوص ، غالبًا ما تكون عملية تخليق الكلام التقليدية هي مسار "الصوت ← الطيف الطيفي (مخطط الطيف الملئي) ← الشكل الموجي".
لكن VALL -E حولت هذه العملية إلى "صوت ← ترميز صوتي منفصل ← شكل موجة":
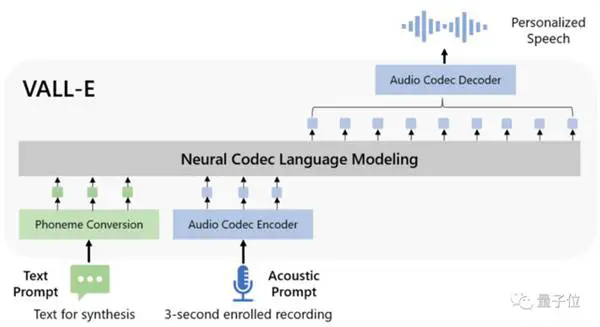
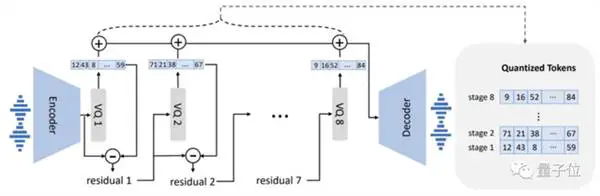
من حيث تصميم النموذج ، يشبه VALL-E أيضًا VQVAE. يقيس الصوت في سلسلة من الرموز المميزة المنفصلة. يعتبر جهاز الكم الأول مسؤولاً عن التقاط المحتوى الصوتي وخصائص الهوية الخاصة بالسماعة ، بينما تكون أجهزة الكم الثانية مسؤولة عن تحسين الإشارة. الذي يبدو أكثر طبيعية:
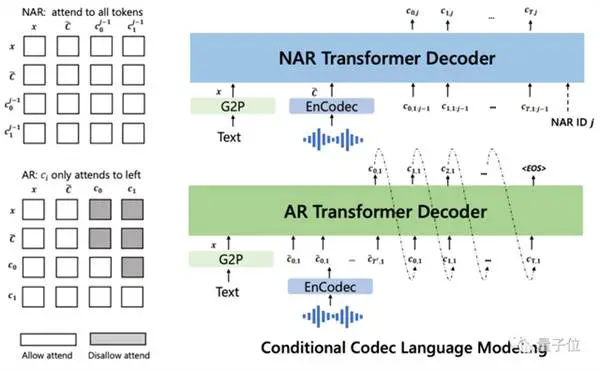
ثم مشروطًا بالنص وموجه الصوت لمدة 3 ثوانٍ ، فإنه يخرج ترميزًا صوتيًا منفصلاً بشكل تلقائي:
ولكن ليس هذا فقط ، بالإضافة إلى تركيب الكلام بدون عينة ، يدعم VALL-E أيضًا تحرير الصوت وإنشاء محتوى صوتي جنبًا إلى جنب مع GPT-3.
يمكن أيضًا استعادة صوت الخلفية المحيط
انطلاقًا من التأثيرات الصوتية المركبة ، يمكن لـ VALL-E استعادة أكثر من مجرد جرس مكبر الصوت.
لا يتم تقليد طبقة الصوت على الفور فحسب ، بل إنها تدعم أيضًا مجموعة متنوعة من سرعات الكلام المختلفة. على سبيل المثال ، هاتان سرعتان مختلفتان للكلام توفرهما VALL-E عند نطق نفس الجملة مرتين ، لكن التشابه اللوني لا يزال مرتفعًا:
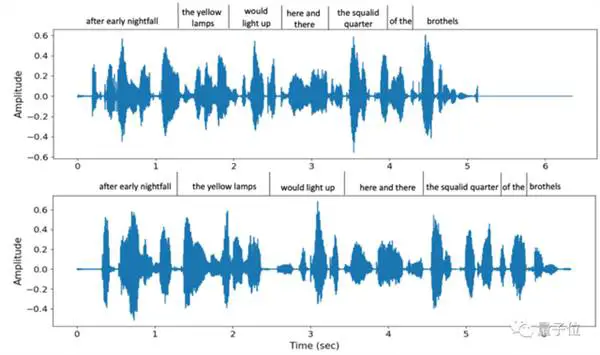
في الوقت نفسه ، يمكن أيضًا استعادة الصوت المحيط بالخلفية للطرف الآخر بدقة.
بالإضافة إلى ذلك ، يمكن لـ VALL-E محاكاة مجموعة متنوعة من مشاعر المتحدث ، بما في ذلك عدة أنواع مثل الغضب والنعاس والحياد والفرح والغثيان.
من الجدير بالذكر أن مجموعة البيانات المستخدمة لتدريب VALL · E ليست كبيرة بشكل خاص.
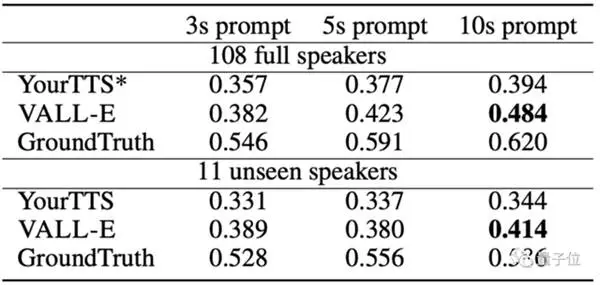
مقارنةً بـ OpenAI's Whisper ، الذي تطلب 680.000 ساعة تدريب صوتي واستخدم فقط أكثر من 7.000 مكبر صوت و 60.000 ساعة تدريب ، تجاوز VALL-E ميزة تحويل النص إلى كلام التي تم تدريبها مسبقًا من حيث التشابه مع نموذج تحويل النص إلى كلام الخاص بـ YourTTS.
علاوة على ذلك ، سمعت YourTTS أصوات 97 من أصل 108 متحدثًا مسبقًا أثناء التدريب ، لكنها لا تزال أقل من VALL-E في الاختبار الفعلي.
أما المجالات التي يمكن تطبيقه فيها:
لا يمكن استخدامه لتقليد صوتك فقط ، مثل مساعدة الأشخاص المعاقين في إكمال محادثة مع الآخرين ، ولكن يمكنك أيضًا استخدامه للتحدث نيابة عنك عندما لا ترغب في ذلك. بالطبع ، يمكن استخدامه أيضًا لتسجيل الكتب الصوتية.
ومع ذلك ، فإن VALL-E ليس مفتوح المصدر بعد وقد تحتاج إلى الانتظار لفترة أطول قليلاً لتجربته.







